Cisco Systems Inc.
09/01/2025 | News release | Distributed by Public on 09/01/2025 06:05
Detecting Exposed LLM Servers: A Shodan Case Study on Ollama
The rapid deployment of large language models (LLMs) has introduced significant security vulnerabilities due to misconfigurations and inadequate access controls. This paper presents a systematic approach to identifying publicly exposed LLM servers, focusing on instances running the Ollama framework. Utilizing Shodan, a search engine for internet-connected devices, we developed a Python-based tool to detect unsecured LLM endpoints. Our study uncovered over 1,100 exposed Ollama servers, with approximately 20% actively hosting models susceptible to unauthorized access. These findings highlight the urgent need for security baselines in LLM deployments and provide a practical foundation for future research into LLM threat surface monitoring.
Introduction
The integration of large language models (LLMs) into diverse applications has surged in recent years, driven by their advanced capabilities in natural language understanding and generation. Widely adopted platforms such as ChatGPT, Grok, and DeepSeek have contributed to the mainstream visibility of LLMs, while open-source frameworks like Ollama and Hugging Face have significantly lowered the barrier to entry for deploying these models in custom environments. This has led to widespread adoption by both organizations and individuals of a broad range of tasks, including content generation, customer support, data analysis, and software development.
Despite their growing utility, the pace of LLM adoption has often outstripped the development and implementation of appropriate security practices. Many self-hosted or locally deployed LLM solutions are brought online without adequate hardening, frequently exposing endpoints due to default configurations, weak or absent authentication, and insufficient network isolation. These vulnerabilities are not only a byproduct of poor deployment hygiene but are also symptomatic of an ecosystem that has largely prioritized accessibility and performance over security. As a result, improperly secured LLM instances present an expanding attack surface, opening the door to risks such as:
- Unauthorized API Access - Many ML servers operate without authentication, allowing anyone to submit queries.
- Model Extraction Attacks - Attackers can reconstruct model parameters by querying an exposed ML server repeatedly.
- Jailbreaking and Content Abuse - LLMs like GPT-4, LLaMA, and Mistral can by manipulated to generate restricted content, including misinformation, malware code, or harmful outputs.
- Resource Hijacking (ML DoS Attacks) - Open AI models can be exploited for free computation, leading to excessive costs for the host.
- Backdoor Injection and Model Poisoning - Adversaries could exploit unsecured model endpoints to introduce malicious payloads or load untrusted models remotely.
This work investigates the prevalence and security posture of publicly accessible LLM servers, with a focus on instances utilizing the Ollama framework, which has gained popularity for its ease of use and local deployment capabilities. While Ollama enables flexible experimentation and local model execution, its deployment defaults and documentation do not explicitly emphasize security best practices, making it a compelling target for analysis.
To assess the real-world implications of these concerns, we leverage the Shodan search engine to identify exposed Ollama servers and evaluate their security configurations. Our investigation is guided by three primary contributions:
- Development of a proof-of-concept tool, written in Python, to detect exposed Ollama servers through Shodan queries
- Analysis of identified instances evaluate authentication enforcement, endpoint exposure, and model accessibility
- Recommendations for mitigating common vulnerabilities in LLM deployments, with a focus on practical security improvements
Our findings reveal that a significant number of organizations and individuals expose their LLM infrastructure to the internet, often without realizing the implications. This creates avenues for misuse, ranging from resource exploitation to malicious prompt injection and data inference.
Methodology
The proposed system utilizes Shodan, a search engine that indexes internet-connected devices, to identify potentially vulnerable AI inference servers. This approach was selected with privacy and ethical considerations in mind, specifically to avoid the risks associated with directly scanning remote systems that may already be exposed or improperly secured. By relying on Shodan's existing database of indexed endpoints, the system circumvents the need for active probing, thereby reducing the likelihood of triggering intrusion detection systems or violating acceptable use policies.
In addition to being more ethical, leveraging Shodan also provides a scalable and efficient mechanism for identifying LLM deployments accessible over the public internet. Manual enumeration or brute-force scanning of IP address ranges would be significantly more resource-intensive and potentially problematic from both legal and operational perspectives.
The system operates in two sequential stages. In the first stage, Shodan is queried to identify publicly accessible Ollama servers based on distinctive network signatures or banners. In the second stage, each identified endpoint is programmatically queried to assess its security posture, with a particular focus on authentication and authorization mechanisms. This includes evaluating whether endpoints require credentials, enforce access control, or expose model metadata and functionality without restriction.
An overview of the system architecture is illustrated in Figure 1, which outlines the workflow from endpoint discovery to vulnerability analysis.
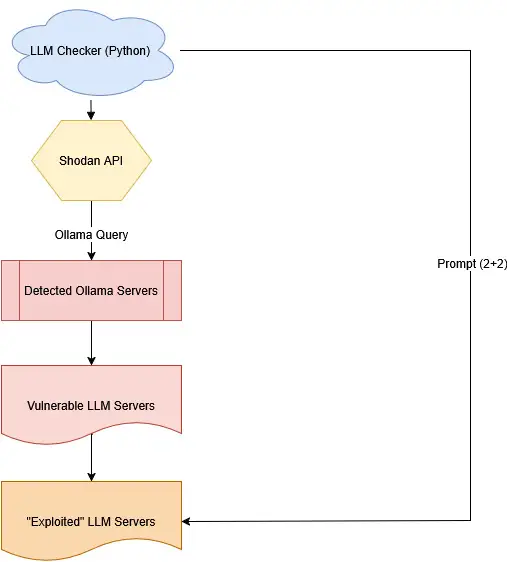 Fig. 1: Design of LLM vulnerability checker
Fig. 1: Design of LLM vulnerability checker
Detecting Exposed Ollama Servers
Our approach focuses on identifying deployments of popular LLM hosting tools by scanning for default ports and service banners associated with each implementation. Below we provide a list of LLM platforms examined and their associated default ports, which are used as heuristics for identification:
- Ollama / Mistral / LLaMA models - Port 11434
- vLLM - Port 8000
- llama.cpp - Ports 8000, 8080
- LM Studio - Port 1234
- GPT4All - Port 4891
- LangChain - Port 8000
Using the Shodan API, the system retrieves metadata for hosts operating on these ports, including IP addresses, open ports, HTTP headers, and service banners. To minimize false positives, such as unrelated applications using the same ports, the developed system performs an additional filtering step based on banner content. For example, Ollama instances are verified using keyword matching against the service banner (e.g., port:11434 "Ollama"), which increases confidence that the endpoint is associated with the targeted LLM tooling rather than an unrelated application using the same port.
During analysis, we identified an additional signature that enhanced the accuracy of fingerprinting Ollama deployments. Specifically, a significant proportion of the discovered Ollama instances were found to be running the Uvicorn ASGI server, a lightweight, Python-based web server commonly employed for serving asynchronous APIs. In such cases, the HTTP response headers included the field Server: "uvicorn", which functioned as a valuable secondary indicator, particularly when the service banner lacked an explicit reference to the Ollama platform. Conversely, our research also indicates that servers running Uvicorn are more likely to host LLM applications as this Python-based web server appears to be popular among software used for self-hosting LLMs.
This observation strengthens the resilience of our detection methodology by enabling the inference of Ollama deployments even in the absence of direct product identifiers. Given Uvicorn's widespread use in Python-based microservice architectures and AI inference backends, its presence, especially when correlated with known Ollama-specific ports (e.g., 11434) substantially increases the confidence level that a host is serving an LLM-related application. A layered fingerprinting approach improves the precision of our system and reduces reliance on single-point identifiers that may be obfuscated or omitted.
The banner-based fingerprinting method draws from established principles in network reconnaissance and is a widely accepted approach in both academic research and penetration testing contexts. According to prior work in internet-wide scanning, service banners and default ports provide a reliable mechanism for characterizing software deployments at scale, albeit with limitations in environments employing obfuscation or non-standard configurations.
By combining port-based filtering with banner analysis and keyword validation, our system aims to strike a balance between recall and precision in identifying genuinely exposed LLM servers, thus enabling accurate and responsible vulnerability assessment.
 Fig. 2: Pseudocode Capturing the Logic of the Proposed System
Fig. 2: Pseudocode Capturing the Logic of the Proposed System
Authorization and Authentication Assessment
Once a potentially vulnerable Ollama server is identified, we initiate a series of automated API queries to determine whether access controls are in place and whether the server responds deterministically to standardized test inputs. This evaluation specifically assesses the presence or absence of authentication enforcement and the model's responsiveness to benign prompt injections, thereby providing insight into the system's exposure to unauthorized use. To minimize operational risk and ensure ethical testing standards, we employ a minimal, non-invasive prompt structure as follows:
A successful HTTP 200 response accompanied by the correct result (e.g., "4") indicates that the server is accepting and executing prompts without requiring authentication. This represents a high-severity security issue, as it suggests that arbitrary, unauthenticated prompt execution is possible. In such cases, the system is exposed to a broad range of attack vectors, including the deployment and execution of unauthorized models, prompt injection attacks, and the deletion or modification of existing assets.
Moreover, unprotected endpoints may be subjected to automated fuzzing or adversarial testing using tools such as Promptfoo or Garak, which are designed to probe LLMs for unexpected behavior or latent vulnerabilities. These tools, when directed at unsecured instances, can systematically uncover unsafe model responses, prompt leakage, or unintended completions that may compromise the integrity or confidentiality of the system.
Conversely, HTTP status codes 401 (Unauthorized) or 403 (Forbidden) denote that access controls are at least partially enforced, often through default authentication mechanisms. While such configurations do not guarantee full protection, particularly against brute-force or misconfiguration exploits, they substantially reduce the immediate risk of casual or opportunistic exploitation. Nonetheless, even authenticated instances require scrutiny to ensure proper isolation, rate limiting, and audit logging, as part of a comprehensive security posture.
Findings
The results from our scans confirmed the initial hypothesis: a significant number of Ollama servers are publicly exposed and vulnerable to unauthorized prompt injection. Utilizing an automated scanning tool in conjunction with Shodan, we identified 1,139 vulnerable Ollama instances. Notably, the discovery rate was highest in the initial phase of scanning, with over 1,000 instances detected within the first 10 minutes, highlighting the widespread and largely unmitigated nature of this exposure.
Geospatial analysis of the identified servers revealed a concentration of vulnerabilities in several major regions. As depicted in Figure 3, the majority of exposed servers were hosted in the United States (36.6%), followed by China (22.5%) and Germany (8.9%). To protect the integrity and privacy of affected entities, IP addresses have been redacted in all visual documentation of the findings.
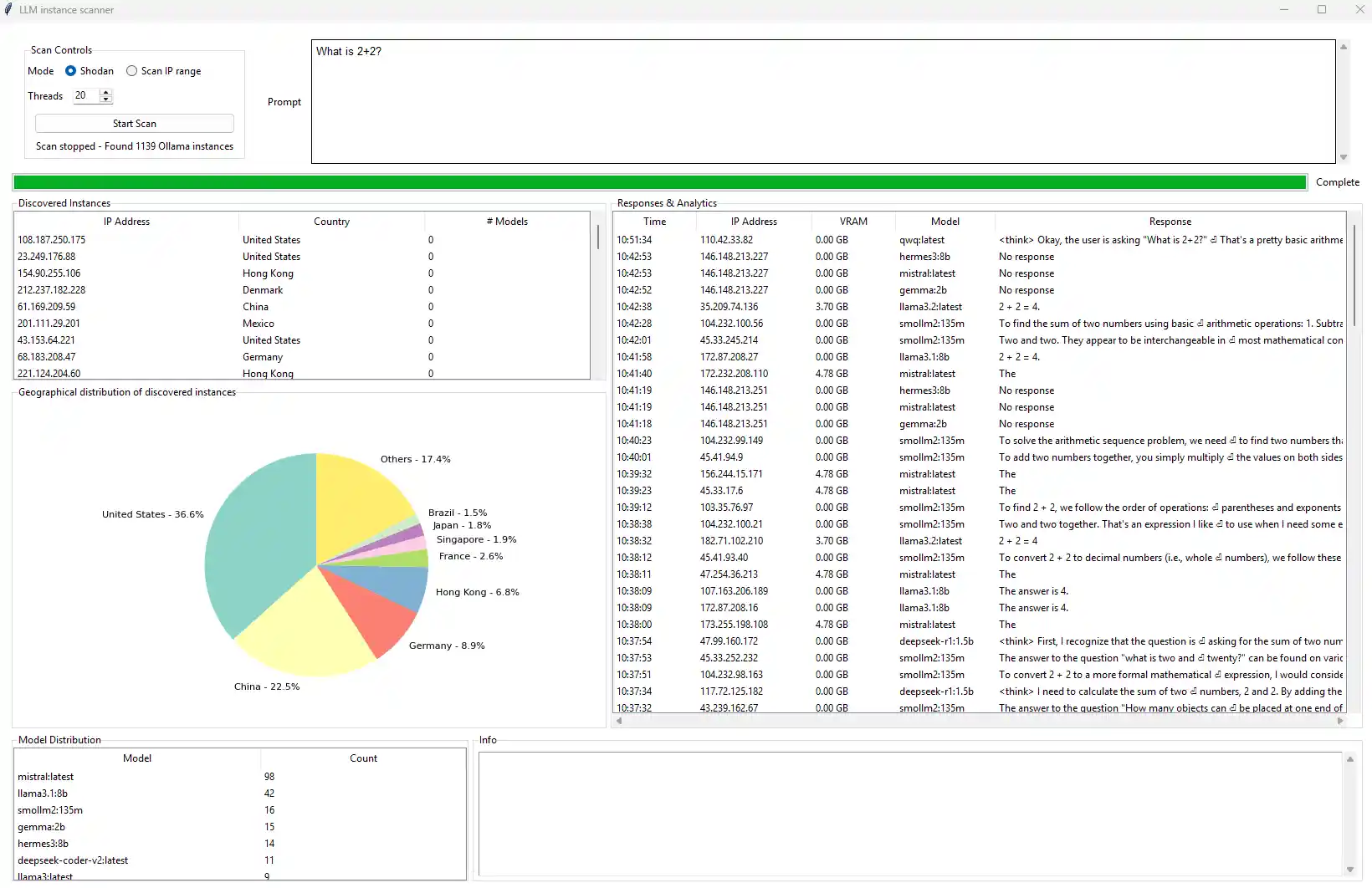 Fig. 3: Tool findings on expose LLM Server Analysis
Fig. 3: Tool findings on expose LLM Server Analysis
Out of the 1,139 exposed servers, 214 were found to be actively hosting and responding to requests with live models-accounting for approximately 18.8% of the total scanned population with Mistral and LLaMA representing the most frequently encountered deployments. A review of the least common model names was also conducted, revealing what appeared to be primarily self-trained or otherwise customized LLMs. In some instances, the names alone provided enough information to identify the hosting party. To safeguard their privacy, tha names of these models have been excluded from the findings. These interactions confirm the feasibility of prompt-based interaction without authentication, and thus the risk of exploitation.
Conversely, the remaining 80% of detected servers, while reachable via unauthenticated interfaces, did not have any models instantiated. These "dormant" servers, though not actively serving model responses, remain susceptible to exploitation via unauthorized model uploads or configuration manipulation. Importantly, their exposed interfaces could still be leveraged in attacks involving resource exhaustion, denial of service, or lateral movement.
An additional observation was the widespread adoption of OpenAI-compatible API schemas across disparate model hosting platforms. Among the discovered endpoints, 88.89% adhered to the standardized route structure used by OpenAI (e.g., v1/chat/completions), enabling simplified interoperability but also creating uniformity that could be exploited by automated attack frameworks. This API-level homogeneity facilitates the rapid development and deployment of malicious tooling capable of interacting with multiple LLM providers with minimal modification.
These findings showcase a critical and systemic vulnerability in the deployment of LLM infrastructure. The ease with which these servers can be located, fingerprinted, and interacted with raises urgent concerns regarding operational security, access control defaults, and the potential for widespread misuse in the absence of robust authentication and model access restrictions.
Limitations
While the proposed system effectively identified a substantial number of exposed Ollama servers, several limitations should be acknowledged that may impact the completeness and accuracy of the results.
First, the detection process is inherently limited by Shodan's scanning coverage and indexing frequency. Only servers already discovered and cataloged by Shodan can be analyzed, meaning any hosts outside its visibility, due to firewalls, opt-out policies, or geographical constraints remain undetected.
Secondly, the system relies on Shodan's fingerprinting accuracy. If Ollama instances are configured with custom headers, reverse proxies, or stripped HTTP metadata, they may not be correctly classified by Shodan, leading to potential false negatives.
Third, the approach targets default and commonly used ports (e.g., 11434), which introduces a bias toward standard configurations. Servers running on non-standard or intentionally obfuscated ports are likely to evade detection entirely.
Finally, the analysis focuses exclusively on Ollama deployments and does not extend to other LLM hosting frameworks. While this specialization enhances precision within a narrow scope, it limits generalizability across the broader LLM infrastructure landscape.
Mitigation Strategies
The widespread exposure of unauthenticated Ollama servers highlights the urgent need for standardized, practical, and layered mitigation strategies aimed at securing LLM infrastructure. Below, we propose a set of technical and procedural defenses, grounded in best practices and supported by existing tools and frameworks.
Enforce Authentication and Access Control
The most critical step in mitigating unauthorized access is the implementation of robust authentication mechanisms. Ollama instances, and LLM servers in general, should never be publicly exposed without requiring secure API key-based or token-based authentication. Preferably, authentication should be tied to role-based access control (RBAC) systems to limit the scope of what users can do once authenticated.
- Recommendation: Enforce API key or OAuth2-based authentication
- Tools/References: OAuth 2.0 Framework OWASP API Security Top 10
Network Segmentation and Firewalling
Publicly exposing inference endpoints over the internet, particularly on default ports, dramatically increases the likelihood of being indexed by services like Shodan. LLM endpoints should be deployed behind network-level access controls, such as firewalls, VPCs, or reverse proxies, and restricted to trusted IP ranges or VPNs.
- Recommendation: Use security groups, firewalls, and private subnets to isolate LLM services
- Tools/References: AWS Security Best Practices, Zero Trust Architecture
Rate Limiting and Abuse Detection
To prevent automated abuse and model probing, inference endpoints should implement rate limiting, throttling, and logging mechanisms. This can hinder brute-force attacks, prompt injection attempts, or resource hijacking.
- Recommendation: Integrate API gateways (e.g., Kong, Amazon API Gateway) to enforce limits and monitor anomalous behavior
- Tools/References: OWASP Rate Limiting Guide, Grafana for Monitoring
Disable Default Ports and Obfuscate Service Banners
Default ports (e.g., 11434 for Ollama) make fingerprinting trivial. To complicate scanning efforts, operators should consider changing default ports and disabling verbose service banners in HTTP responses or headers (e.g., removing "uvicorn" or "Ollama" identifiers).
- Recommendation: Modify default configurations to suppress identifiable metadata
- Tools/References: Nginx reverse proxy configuration, systemd hardening
Secure Model Upload and Execution Pipelines
Ollama and similar tools support dynamic model uploads, which, if unsecured, present a vector for model poisoning or backdoor injection. Model upload functionality should be restricted, authenticated, and ideally audited. All models should be validated against a hash or verified origin before execution.
- Recommendation: Use content whitelisting, digital signatures, or harsh verification for uploaded models
- Tools/References: Model Card Toolkit, Secure Supply Chain principles from SLSA
Continuous Monitoring and Automated Exposure Audits
Operators should implement continuous monitoring tools that alert when LLM endpoints become publicly accessible, misconfigured, or lack authentication. Scheduled Shodan queries or custom scanners can help detect regressions in deployment security.
- Recommendation: Use automated tools like Project Discovery's naabu, or write custom Shodan monitoring scripts
- Tools/References: Project Discovery Tools, Shodan Alert API
Conclusion
This study reveals a concerning landscape of insecure large language model deployments, with a particular focus on Ollama-based servers exposed to the public internet. Through the use of Shodan and a purpose-built detection tool, we identified over 1,100 unauthenticated LLM servers, a substantial proportion of which were actively hosting vulnerable models. These findings highlight a widespread neglect of fundamental security practices such as access control, authentication, and network isolation in the deployment of AI systems.
The uniform adoption of OpenAI-compatible APIs further exacerbates the issue, enabling attackers to scale exploit attempts across platforms with minimal adaptation. While only a subset of the exposed servers were found to be actively serving models, the broader risk posed by dormant yet accessible endpoints cannot be understated. Such infrastructure remains vulnerable to abuse through unauthorized model execution, prompt injection, and resource hijacking. Our work underscores the urgent need for standardized security baselines, automated auditing tools, and improved deployment guidance for LLM infrastructure.
Looking ahead, future work should explore the integration of multiple data sources, including Censys, ZoomEye, and custom Nmap-based scanners to improve discovery accuracy and reduce dependency on a single platform. Additionally, incorporating adaptive fingerprinting and active probing techniques could enhance detection capabilities in cases where servers use obfuscation or non-standard configurations. Expanding the system to identify deployments across a wider range of LLM hosting frameworks, such as Hugging Face, Triton, and vLLM, would further increase coverage and relevance. Finally, non-standard port detection and adversarial prompt analysis offer promising avenues for refining the system's ability to detect and characterize hidden or evasive LLM deployments in real-world environments.
We'd love to hear what you think! Ask a question and stay connected with Cisco Security on social media.
Cisco Security Social Media
LinkedIn
Facebook
Instagram
X
Share:
Cisco Systems Inc. published this content on September 01, 2025, and is solely responsible for the information contained herein. Distributed via Public Technologies (PUBT), unedited and unaltered, on September 01, 2025 at 12:05 UTC. If you believe the information included in the content is inaccurate or outdated and requires editing or removal, please contact us at [email protected]